2019. 5. 21. 19:49ㆍIT-공부하자
가상환경의 GuestOS 에서 HostOS 의 HW를 직접적으로 사용하는 걸 뜻하는 걸로
알고 뒤지다 보니 생각보다 범용적인 의미로 사용되는 단어이네요.
음악 이나 기타 다른 곳에서도 Data가 중간에 가공되지 않고 그대로 전달되는 의미로
그러나 일단 가상화에서 passthrough 에 대해서 알아보겠습니다. 자료는 역시 많습니다.
(펌 : http://jowon.blogspot.com/2010/01/linux-pci-passthrough.html )
Linux 가상화와 PCI passthrough
M. Tim Jones, Independent author, Emulex 요약: 프로세서 분야에서는 가상화된 환경의 성능 향상을 위한 많은 발전이 있었습니다. 그렇다면 I/O 분야에서는 어떤 발전이 있었을까요? 이 기사에서는 I/O 성능 향상 기술인...
jowon.blogspot.com
Linux 가상화와 PCI passthrough
M. Tim Jones, Independent author, Emulex
요약: 프로세서 분야에서는 가상화된 환경의 성능 향상을 위한 많은 발전이 있었습니다. 그렇다면 I/O 분야에서는 어떤 발전이 있었을까요? 이 기사에서는 I/O 성능 향상 기술인 장치(또는 PCI) passthrough에 대해 설명합니다. 이 혁신 기술은 Intel(VT-d) 또는 AMD(IOMMU)의 하드웨어 지원을 사용하여 PCI 장치의 성능을 높여 줍니다.
플랫폼 가상화는 효율적인 리소스 사용을 위해 두 개 이상의 운영 체제에서 하나의 플랫폼을 공유하는 것을 말한다. 하지만 여기에서 플랫폼은 단순히 프로세서만을 의미하는 것이 아니라 스토리지, 네트워크 및 기타 하드웨어 리소스를 비롯하여 플랫폼을 구성하는 다른 중요 요소까지도 포함된 의미이다. 프로세서나 스토리지와 같은 일부 하드웨어 리소스는 쉽게 가상화할 수 있지만 비디오 어댑터나 직렬 포트와 같이 가상화하기 어려운 하드웨어 리소스도 있다. 하지만 PCI(Peripheral Component Interconnect) passthrough를 사용하면 공유할 수 없거나 공유 효율성이 낮은 리소스를 효과적으로 사용할 수 있다. 이 기사에서는 passthrough의 개념을 살펴보고 하이퍼바이저에서 passthrough를 구현하는 방법에 대해 알아본 후 이 혁신적인 최신 기술을 지원하는 하이퍼바이저에 대해 자세히 설명한다.
플랫폼 장치 에뮬레이션
그림1. 하이퍼바이저 기반 장치 에뮬레이션
{kind=link}
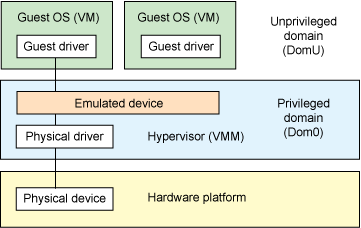
passthrough를 시작하기 전에 먼저 두 가지 최신 하이퍼바이저 아키텍처에서 장치 에뮬레이션이 작동하는 방법을 살펴보자. 첫 번째 아키텍처에서는 장치 에뮬레이션이 하이퍼바이저 내에 통합된 반면 두 번째 아키텍처에서는 하이퍼바이저 외부의 애플리케이션에서 장치 에뮬레이션을 처리한다.
하이퍼바이저 내의 장치 에뮬레이션은 VMware 워크스테이션 제품에서 일반적으로 구현하는 방법이다(운영 체제 기반 하이퍼바이저). 이 모델에서는 가상 디스크, 가상 네트워크 어댑터 및 기타 필수 플랫폼 요소를 비롯하여 다양한 게스트 운영 체제에서 공유할 수 있는 공통 장치에 대한 에뮬레이션이 하이퍼바이저에 포함되어 있다. 그림 1에서 이 특별한 모델을 볼 수 있다.
두 번째 아키텍처는 사용자 공간 장치 에뮬레이션이다(그림 2 참조). 이름에서 알 수 있듯이 이 아키텍처에서는 장치 에뮬레이션이 하이퍼바이저 내에 포함되지 않는 대신 사용자 공간에서 구현된다. 장치 에뮬레이션을 지원하는 QEMU(장치 에뮬레이션과 하이퍼바이저를 모두 제공함)는 수많은 독립 하이퍼바이저(KVM(Kernel-based Virtual Machine) 및 VirtualBox)에서 사용된다. 이 모델의 장점은 장치 에뮬레이션이 하이퍼바이저와 독립되어 있기 때문에 여러 하이퍼바이저에서 장치 에뮬레이션을 공유할 수 있다는 것이다. 또한 이 기능을 사용하면 권한이 있는 상태에서 작동하는 하이퍼바이저에 부담을 주지 않고 임의의 장치 에뮬레이션을 수행할 수 있다.
그림2. 사용자 공간 장치 에뮬레이션
{kind=link}

장치 에뮬레이션을 하이퍼바이저에서 사용자 공간으로 옮기면 몇 가지 뚜렷한 장점을 얻을 수 있으며 그 중에서 가장 중요한 장점은 TCB(trusted computing base)와 관련되어 있다. 시스템의 TCB는 보안에 중요한 모든 구성 요소의 세트이다. 당연한 말이겠지만 만일 시스템을 최소화하게 되면 버그의 가능성도 줄어들기 때문에 보다 더 안전한 시스템이 될 것이다. 이와 동일한 아이디어가 하이퍼바이저에도 적용된다. 하이퍼바이저는 독립된 여러 게스트 운영 체제를 분리하기 때문에 보안이 매우 중요하다. 하이퍼바이저의 코드 양이 적을수록 즉, 장치 에뮬레이션을 더 적은 권한이 요구되는 사용자 공간에서 구현하면 신뢰할 수 없는 사용자에게 권한이 주어지는 경우가 줄어든다.
하이퍼바이저 기반 장치 에뮬레이션의 또 다른 형태로는 병렬화된 드라이버가 있다. 이 모델에서는 하이퍼바이저에 실제 드라이버가 포함되며, 각각의 게스트 운영 체제에 하이퍼바이저 드라이버와 함께 작동하는 하이퍼바이저 인식 드라이버(병렬 가상화된 또는 PV 드라이버)가 포함된다.
장치 에뮬레이션이 하이퍼바이저나 게스트 VM(Virtual Machine)에서 발생하는지 여부에 상관 없이 에뮬레이션 방법은 비슷하다. 장치 에뮬레이션은 특정 장치(예: Novell NE1000 네트워크 어댑터)나 특정 유형의 디스크(예: IDE(Integrated Device Electronics) 드라이브)를 모방할 수 있다. 실제 하드웨어가 크게 다를 수 있다. 예를 들어, 게스트 운영 체제에는 IDE 드라이브가 에뮬레이션되어 있고 실제 하드웨어 플랫폼에서는 SATA(serial ATA) 드라이브를 사용할 수 있다. 이렇게 하면 모든 게스트 운영 체제에서 고급 드라이브 유형을 지원하지 않아도 많은 운영 체제에서 공통으로 지원되는 IDE를 공통으로 사용할 수 있기 때문에 큰 효과를 얻을 수 있다.
장치 passthrough
위에서 설명한 두 가지 장치 에뮬레이션 모델에서 살펴본 바로는 장치를 공유하기 위해 몇 가지 추가 요소가 필요하다. 즉, 장치 에뮬레이션이 하이퍼바이저에서 수행되던 독립 VM 내의 사용자 공간에서 수행되던 상관 없이 오버헤드가 있다는 것을 알 수 있다. 여러 게스트 운영 체제에서 장치를 공유할 필요가 있는 한 이 오버헤드는 충분한 가치를 지니고 있다. 하지만 이러한 공유가 필요 없을 경우에는 보다 효율적인 방법으로 장치를 공유할 수 있다.
크게 말해서 장치 passthrough는 장치를 배타적으로 사용할 수 있도록 지정된 게스트 운영 체제에 전용 장치를 제공하는 것이다(그림 3 참조). 그렇다면 이렇게 했을 때 얻을 수 있는 장점은 무엇일까? 물론 장치 passthrough가 유용한 이유는 여러 가지이다. 그 중에서 가장 중요한 두 가지 이유를 들자면 첫 번째가 성능이고, 두 번째는 본질적으로 공유할 수 없는 장치를 배타적으로 사용할 수 있다는 것이다.
그림3. Hypervisor 내에서의 PassThrough
{kind=link}

성능 면에서 보았을 때, 장치 passthrough를 사용하면 성능 손실이 거의 발생하지 않는다. 따라서 장치 passthrough는 하이퍼바이저를 통과할 때(하이퍼바이저 내의 드라이버나 사용자 공간 에뮬레이션에 대한 하이퍼바이저를 통과할 때) 발생하는 경합과 성능 저하 때문에 가상화를 채택하지 않은 네트워크 애플리케이션(또는 디스크 입출력이 많은 애플리케이션)에 이상적인 기술이다. 하지만 특정 게스트에 장치를 할당하는 방법은 해당 장치를 공유할 수 없는 경우에도 유용하다. 예를 들어, 시스템에 여러 개의 비디오 어댑터가 있을 경우 이러한 어댑터를 고유한 게스트 도메인에 직접 연결할 수 있다.
마지막으로 하나의 게스트 도메인에서만 사용하는 특수 PCI 장치나 하이퍼바이저에서 지원하지 않기 때문에 게스트에 직접 연결해야 하는 장치가 있을 수 있다. 개별 USB 포트를 지정된 도메인으로 분리하거나 직렬 포트(그 자체로는 공유할 수 없는 장치)를 특정 게스트에 분리할 수 있다.
장치 에뮬레이션에 대한 이해
초기의 장치 에뮬레이션에서는 하이퍼바이저 내에 장치 인터페이스의 섀도우를 구현하여 게스트 운영 체제에 가상 인터페이스를 제공했다. 이 가상 인터페이스는 장치(예: 섀도우 PCI)를 나타내는 가상 주소 공간과 가상 인터럽트를 포함한 예상 인터페이스로 구성되어 있다. 하지만 가상 인터페이스와 통신하는 장치 드라이버와 이 통신을 실제 하드웨어로 변환하는 하이퍼바이저를 사용하면 상당한 수준의 오버헤드가 발생하며 특히, 네트워크 어댑터와 같은 고사양 장치의 경우에는 오버헤드의 수준이 더욱 높아진다.
Xen에서 대중화시킨 PV 방법(앞 섹션에서 설명함)은 게스트 운영 체제 시스템 드라이버가 가상화되고 있음을 인식하도록 하여 성능의 저하를 줄인다. 이 경우 게스트 운영 체제는 네트워크 어댑터와 같은 장치에 대한 PCI 공간 대신 상위 레벨 추상화를 제공하는 네트워크 어댑터 API(예: 패킷 인터페이스)를 본다. 이 방법의 단점은 게스트 운영 체제를 PV에 맞게 수정해야 한다는 것이며 장점은 손실이 거의 없는 수준의 성능을 얻을 수도 있다는 것이다.
초기의 장치 passthrough에서는 하이퍼바이저가 소프트웨어 기반 메모리 관리(게스트 운영 체제 주소 공간을 트러스트된 호스트 주소 공간으로 변환)를 제공하는 씬 에뮬레이션 모델을 사용했다. 그리고 초기 시도에서는 장치를 특정 게스트 운영 체제로 분리할 수 있는 방법을 제공하기는 했지만 이로 인해 대규모 가상화 환경에 필요한 성능과 확장성이 부족하다는 단점이 있었다. 다행스럽게도 프로세서 공급자가 하이퍼바이저뿐만 아니라 인터럽트 가상화 및 DMA(Direct Memory Access) 지원을 포함한 장치 passthrough의 논리까지도 지원하는 명령어를 갖춘 차세대 프로세서를 개발했다. 따라서 하이퍼바이저 아래에 있는 실제 장치에 대한 액세스를 확인하고 에뮬레이션하는 대신 새 프로세서는 효율적인 장치 passthrough를 위해 DMA 주소 변환 및 권한 검사 기능을 제공한다.
장치 passthrough를 위한 하드웨어 지원
Intel과 AMD 모두 자사의 새로운 프로세서 아키텍처에서 장치 passthrough에 대한 지원과 하이퍼바이저를 지원하는 새로운 명령어를 제공한다. Intel에서는 이 옵션을 VT-d(Virtualization Technology for Directed I/O))라고 부르고 AMD에서는 IOMMU(I/O Memory Management Unit)라고 부른다. 두 경우 모두 새 CPU가 PCI의 실제 주소를 게스트의 가상 주소에 맵핑한다. 이 맵핑이 발생하면 하드웨어가 액세스를 보호하게 되며, 결과적으로 게스트 운영 체제에서는 가상화되지 않은 시스템인 것처럼 장치를 사용할 수 있다. 게스트를 실제 메모리에 맵핑하는 기능 외에도 다른 게스트(또는 하이퍼바이저)의 액세스를 차단하는 분리 기능이 제공된다. 이외에도 Intel 및 AMD CPU는 다양한 가상화 기능을 제공한다. 참고자료 섹션에서 자세한 정보를 확인할 수 있다.
또 하나의 혁신 기술로서 인터럽트를 많은 수의 VM으로 확장할 수 있는 MSI(Message Signaled Interrupts)라는 기능이 있다. MSI는 실제 인터럽트 핀을 통해 게스트에 연결하는 대신 인터럽트를 보다 쉽게 가상화할 수 있는 메시지로 변환한다(수천 개의 개별 인터럽트로 확장). PCI 버전 2.2부터 도입된 MSI는 PCIe(PCI Express)에서도 사용할 수 있으며, PCIe에서는 패브릭을 사용하여 다수의 장치로 확장할 수 있다. MSI는 인터럽트 소스를 분리(소프트웨어를 통해 멀티플렉싱 또는 라우팅되어야 하는 실제 핀과는 반대되는 방법)할 수 있기 때문에 I/O 가상화에 이상적이다.
장치 passthrough를 위한 하이퍼바이저 지원
가상화 기능이 강화된 최신 프로세서 아키텍처를 기반으로 수많은 하이퍼바이저 및 가상화 솔루션에서 장치 passthrough를 지원하고 있다. Xen과 KVM뿐만 아니라 다른 여러 하이퍼바이저에서도 장치 passthrough에 대한 지원(VT-d 또는 IOMMU 사용)을 찾아볼 수 있다. 대부분의 경우에는 passthrough를 지원하기 위해 게스트 운영 체제(도메인 0)를 컴파일해야 하며, 이 컴파일 작업은 커널 빌드 타임 옵션으로 제공된다. 또한 pciback을 사용하여 Xen에서 수행했던 것처럼 호스트 VM에서 장치를 숨겨야 한다. PCI에서는 PCIe-to-PCI 브리지 뒤에 있는 PCI 장치를 동일한 도메인에 할당해야 한다는 등의 약간의 제한 사항이 있지만 PCIe에서는 이러한 제한 사항이 없다.
또한 libvirt(및 virsh)에도 장치 passthrough에 구성 지원이 있으며, 이 구성 지원은 기본 하이퍼바이저에 사용되는 구성 스키마에 대한 추상화 기능을 제공한다.
장치 passthrough와 관련된 문제점
실시간 마이그레이션이 필요할 경우 장치 passthrough와 관련된 한 가지 문제가 발생한다. 실시간 마이그레이션은 VM을 일시 중단한 후 VM의 다시 시작 위치를 가리키는 새로운 실제 호스트로 마이그레이션하는 기능이다. 이 기능은 실제 호스트 네트워크 상에서 VM의 로드 밸런싱을 지원하는 뛰어난 기능이지만 passthrough 장치를 사용할 경우 문제가 발생한다. 해결해야 하는 문제점으로 PCI 핫플러그(여러 스펙이 있음)가 있다. PCI 장치와 지정된 커널 간의 통신을 지원하는 PCI 핫플러그는 VM을 새 호스트 시스템에 있는 하이퍼바이저로 마이그레이션하려는 경우에 이상적이다(장치를 언플러그하지 않아도 새 하이퍼바이저에서 나중에 자동으로 플러그됨). 가상 네트워크 어댑터와 같이 장치가 에뮬레이션될 때 에뮬레이션에서 실제 하드웨어를 추상화하는 계층을 제공한다. 이렇게 하면 가상 네트워크 어댑터를 VM 내에서 쉽게 마이그레이션할 수 있다(여러 논리적 네트워크 어댑터를 동일한 인터페이스에 연결할 수 있는 Linux® 본딩 드라이버(bonding driver)에서도 지원됨).
I/O 가상화의 다음 단계
I/O 가상화의 다음 단계는 오늘날 실제로 발생하고 있다. 예를 들어, PCIe에 가상화에 대한 지원이 있다. 서버 가상화에 이상적인 한 가지 가상화 개념으로 SR-IOV(Single-Root I/O Virtualization)가 있다. PCI-Special Interest Group 또는 PCI-SIG에서 개발한 이 가상화 기술은 단일 루트 복합 인스턴스 내에서 장치 가상화를 제공한다. 이 경우에는 단일 서버에 있는 여러 VM이 장치를 공유한다. 또 다른 변형 기술인 멀티 루트 IOV는 더 큰 토폴로지(예를 들어, 여러 서버가 하나 이상의 PCIe 장치에 액세스할 수 있는 블레이드 서버)를 지원한다. 어떤 의미에서 이 기술은 서버, 종단 장치 및 스위치를 포함한 대규모 장치 네트워크까지도 지원한다.
SR-IOV를 사용하면 PCIe 장치에서 수많은 실제 PCI 기능뿐만 아니라 I/O 장치의 리소스를 공유하는 가상 기능의 세트까지도 내보낼 수 있다. 그림 4에서는 간단한 형태의 서버 가상화 아키텍처를 보여 준다. 이 모델에서는 가상화가 종단 장치에서 발생하기 때문에 passthrough가 필요하지 않으며 하이퍼바이저에서 가상 기능을 VM에 맵핑하는 것만으로도 분리의 보안과 함께 원시 장치의 성능을 얻을 수 있다.
그림 4. SR-IOV를 이용한 PassThrough
{kind=link}

추가 주제
가상화는 약 50년 동안 개발되고 있는 기술이지만 I/O 가상화에 대한 관심은 이제야 확산되고 있다. 상용 프로세서의 가상화 지원도 고작 5년 정도에 불과하다. 따라서 지금이 바로 진정한 의미에서의 플랫폼 및 I/O 가상화가 시작되는 출발점이라고 해도 과언이 아닐 것이다. 또한 클라우드 컴퓨팅과 같은 미래 아키텍처의 주요 요소로 자리 잡을 가상화는 앞으로 그 발전을 눈 여겨 볼만한 흥미로운 기술임에 틀림 없다. 일반적으로 이러한 새 아키텍처를 선도적으로 지원하는 Linux이기에 최신 커널(2.6.27 이상)에도 가상화와 관련된 이러한 신기술에 대한 지원이 포함되어 있다.
부록 G. PCI 통과(passthrough)를 위한 호스트 설정 - Red Hat Customer Portal
The Red Hat Customer Portal delivers the knowledge, expertise, and guidance available through your Red Hat subscription.
access.redhat.com
PCI 통과(passthrough)를 활성화하면 가상 머신이 마치 호스트 장치에 직접 연결된 것처럼 호스트 장치를 사용할 수 있습니다. PCI 통과 기능을 활성화하려면 가상화 확장 및 IOMMU 기능이 활성화되어야 합니다. 다음의 절차를 사용하는 경우 호스트를 재부팅해야 합니다. 호스트가 이미 Manager에 연결되어 있는 경우 다음의 절차를 실행하기 전에 호스트를 유지 관리 모드로 전환합니다.
전제 조건:
-
호스트 하드웨어가 PCI 장치 통과 및 할당 요구 사항을 충족하는지 확인합니다. 자세한 정보는 2.2.4절. “PCI 장치 요구 사항”을 참조하십시오.
절차 G.1. PCI 통과(passthrough)를 위한 호스트 설정
-
BIOS에서 가상화 확장 및 IOMMU 확장 기능을 활성화합니다. 자세한 내용은 Red Hat Enterprise Linux 가상화 및 관리 가이드에 있는 BIOS에서 Intel VT-x 및 AMD-V 가상화 하드웨어 확장 활성화를 참조하십시오.
-
호스트를 Manager에 추가할 때 호스트 장치 통과 & SR-IOV 확인란을 선택하거나 grub설정 파일을 수동으로 편집하여 커널에서 IOMMU 플래그를 활성화합니다.
-
관리 포털에서 IOMMU 플래그를 활성화하려면 관리 가이드에 있는 Red Hat Virtualization Manager에 호스트 추가 및 커널 설정을 참조하십시오.
-
grub 설정 파일을 수동으로 편집하려면 절차 G.2. “IOMMU 수동 활성화”를 참조하십시오.
-
-
GPU 통과(Passthrough)를 위해서는 호스트 및 게스트 시스템 모두에 추가적인 설정 단계를 실행해야 합니다. 자세한 내용은 관리 가이드에 있는 GPU 통과에 필요한 호스트 및 게스트 시스템 준비를 참조하십시오.
절차 G.2. IOMMU 수동 활성화
-
GRUB 설정 파일을 편집해서 IOMMU를 활성화합니다.
참고
IBM POWER8 하드웨어를 사용하는 경우 기본값으로 IOMMU가 활성화되어 있으므로 이 단계를 건너뜁니다.
-
Intel의 경우 시스템을 부팅한 후 grub 설정 파일의 GRUB_CMDLINE_LINUX행 끝에 intel_iommu=on를 덧붙입니다.
# vi /etc/default/grub ... GRUB_CMDLINE_LINUX="nofb splash=quiet console=tty0 ... intel_iommu=on ... -
AMD의 경우 시스템을 부팅한 후 grub 설정 파일의 GRUB_CMDLINE_LINUX행 끝에 amd_iommu=on를 덧붙입니다.
# vi /etc/default/grub ... GRUB_CMDLINE_LINUX="nofb splash=quiet console=tty0 ... amd_iommu=on ...
참고
intel_iommu=on 또는 amd_iommu=on이 작동한다면 intel_iommu=pt 또는 amd_iommu=pt로 바꿔 봅니다. pt 옵션을 사용해서 통과(passthrough)에 사용되는 장치만 IOMMU가 활성화하고 더 나은 호스트 성능을 제공합니다. 하지만 모든 하드웨어에서 이 옵션이 지원되지는 않을 수 있습니다. 사용자 호스트에 pt 옵션이 작동하지 않으면 이전 옵션으로 돌아갑니다.
하드웨어가 인터럽트 리매핑(interrupt remapping)을 지원하지 않아서 통과가 실패하는 경우 가상 머신이 신뢰할 수 있다면 allow_unsafe_interrupts 옵션을 활성화할 수도 있습니다. allow_unsafe_interrupts 옵션을 활성화하면 잠재적으로 호스트가 가상 머신으로부터 MSI 공격에 노출될 수 있어서 기본값으로 활성화되어 있지 않습니다. 해당 옵션을 활성화하는 방법은 다음과 같습니다:# vi /etc/modprobe.d options vfio_iommu_type1 allow_unsafe_interrupts=1
-
-
변경 사항을 적용하려면 grub.cfg 파일을 새로고침하고 호스트를 재부팅합니다:
# grub2-mkconfig -o /boot/grub2/grub.cfg# reboot
SR-IOV를 활성화하고 가상 머신에 전용 가상 NIC를 할당하는 방법은 https://access.redhat.com/articles/2335291을 참조하시기 바랍니다.
(펌 : https://docs.oracle.com/cd/E97728_01/F12469/html/pcipassthrough.html )
2.5. PCI Passthrough
When running on Linux hosts with a kernel version later than 2.6.31, experimental host PCI devices passthrough is available. This feature enables a guest to directly use physical PCI devices on the host, even if host does not have drivers for this particul
docs.oracle.com
2.5. PCI Passthrough
When running on Linux hosts with a kernel version later than 2.6.31, experimental host PCI devices passthrough is available.
Note
The PCI passthrough module is shipped as a Oracle VM VirtualBox extension package, which must be installed separately. See Installing Oracle VM VirtualBox and Extension Packs.
This feature enables a guest to directly use physical PCI devices on the host, even if host does not have drivers for this particular device. Both, regular PCI and some PCI Express cards, are supported. AGP and certain PCI Express cards are not supported at the moment if they rely on Graphics Address Remapping Table (GART) unit programming for texture management as it does rather non-trivial operations with pages remapping interfering with IOMMU. This limitation may be lifted in future releases.
To be fully functional, PCI passthrough support in Oracle VM VirtualBox depends upon an IOMMU hardware unit which is not yet too widely available. If the device uses bus mastering, for example it performs DMA to the OS memory on its own, then an IOMMU is required. Otherwise such DMA transactions may write to the wrong physical memory address as the device DMA engine is programmed using a device-specific protocol to perform memory transactions. The IOMMU functions as translation unit mapping physical memory access requests from the device using knowledge of the guest physical address to host physical addresses translation rules.
Intel's solution for IOMMU is called Intel Virtualization Technology for Directed I/O (VT-d), and AMD's solution is called AMD-Vi. Check your motherboard datasheet for the appropriate technology. Even if your hardware does not have a IOMMU, certain PCI cards may work, such as serial PCI adapters, but the guest will show a warning on boot and the VM execution will terminate if the guest driver will attempt to enable card bus mastering.
It is very common that the BIOS or the host OS disables the IOMMU by default. So before any attempt to use it please make sure that the following apply:
-
Your motherboard has an IOMMU unit.
-
Your CPU supports the IOMMU.
-
The IOMMU is enabled in the BIOS.
-
The VM must run with VT-x/AMD-V and nested paging enabled.
-
Your Linux kernel was compiled with IOMMU support, including DMA remapping. See the CONFIG_DMAR kernel compilation option. The PCI stub driver (CONFIG_PCI_STUB) is required as well.
-
Your Linux kernel recognizes and uses the IOMMU unit. The intel_iommu=on boot option could be needed. Search for DMAR and PCI-DMA in kernel boot log.
Once you made sure that the host kernel supports the IOMMU, the next step is to select the PCI card and attach it to the guest. To figure out the list of available PCI devices, use the lspci command. The output will look as follows:
01:00.0 VGA compatible controller: ATI Technologies Inc Cedar PRO [Radeon HD 5450] 01:00.1 Audio device: ATI Technologies Inc Manhattan HDMI Audio [Mobility Radeon HD 5000 Series] 02:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8111/8168B PCI Express Gigabit Ethernet controller (rev 03) 03:00.0 SATA controller: JMicron Technology Corp. JMB362/JMB363 Serial ATA Controller (rev 03) 03:00.1 IDE interface: JMicron Technology Corp. JMB362/JMB363 Serial ATA Controller (rev 03) 06:00.0 VGA compatible controller: nVidia Corporation G86 [GeForce 8500 GT] (rev a1)
The first column is a PCI address, in the format bus:device.function. This address could be used to identify the device for further operations. For example, to attach a PCI network controller on the system listed above to the second PCI bus in the guest, as device 5, function 0, use the following command:
VBoxManage modifyvm "VM name" --pciattach 02:00.0@01:05.0
To detach the same device, use:
VBoxManage modifyvm "VM name" --pcidetach 02:00.0
Please note that both host and guest could freely assign a different PCI address to the card attached during runtime, so those addresses only apply to the address of the card at the moment of attachment on the host, and during BIOS PCI init on the guest.
If the virtual machine has a PCI device attached, certain limitations apply:
-
Only PCI cards with non-shared interrupts, such as those using MSI on the host, are supported at the moment.
-
No guest state can be reliably saved or restored. The internal state of the PCI card cannot be retrieved.
-
Teleportation, also called live migration, does not work. The internal state of the PCI card cannot be retrieved.
-
No lazy physical memory allocation. The host will preallocate the whole RAM required for the VM on startup, as we cannot catch physical hardware accesses to the physical memory.
'IT-공부하자' 카테고리의 다른 글
| [가상화] Virtualizaion 개념 (펌) (0) | 2019.05.21 |
|---|